金融界网站讯 近日,浙江大学-同盾科技人工智能联合实验室发表的论文《Rethinking the Bottom-Up Framework for Query-based Video Localization》被人工智能顶级会议AAAI 2020收录,在现场被评选为口头报告论文(oral presentation), 值得一提的是整个大会口头报告论文接受率仅为5.9%。
论文提出Bottom-Up视频定位算法创新,表现超越了Top-Down SOTA(State-of-the-Art,目前最优)模型算法,在解决视频片段的检索任务,改良当下自底向上模型的设计缺陷上,取得新突破。创新成果未来对于视频内容检索,内容审核与合规风控管理体系的建设具有重要的应用价值。
自“浙江大学-同盾科技人工智能联合实验室”成立以来,双方在学术研究领域不断取得重要成果。联合实验室于2018年正式挂牌成立,并由浙江大学计算机学院教授庄越挺,同盾科技创始人、CEO蒋韬担任联席主任。
联合实验室研究课题面向人工智能基础技术,包括金融领域应用的联邦学习算法研究、风控环境领域的自然语言处理、复杂网络的异常检测方法,视觉内容理解与推理算法研究等方向。旨在智能分析决策领域取得基础理论和核心技术的突破,并与金融、互联网、交通、政府及公共事务等领域相结合,推动产业智能化升级。

本次收录在AAAI 2020的论文是联合实验室一系列重要成果的缩影,该论文通过分析目前视频片段检索框架(自顶向下模型和稀疏型自底向上模 型)的优缺点,提出一种全新密集型自底向上的框架,可以避免现有框架的所有缺点。同时,研究团队设计了一个基于图卷积的特征金字塔层,来增强骨干网络的编码能力。
以下为论文节选精华:
在基于查询的视频定位任务中,重新评估了以往表现不尽如人意的Bottom-Up网络框架的潜力。文章通过重新设计框架的backbone和head network,提出了Graph-FPN with Dense Predictions (GDP)模型,在两类基于查询的视频定位任务上超越了Top-Down SOTA模型。
视频定位算法框架现状
现有的视频定位算法可以被归类为两大类:Top-Down以及Bottom-Up。Top-Down方法将整段视频预切割成一系列候选短视频,接着对每一段候选视频进行分类和回归;Bottom-up方法将query和整段视频作为输入,输出每一帧作为“开始/结束”标记的概率分布。
尽管当前Top-Down方法在表现上比Bottom-Up方法要更加优秀,但是Top-Down模型有一些非常糟糕的限制条件需要注意:首先模型表现对例如temporal scale或者candidate number的启发式规则很敏感;其次为了提高模型的召回率,通常我们需要非常密集地选择候选短视频,这就导致了Top-Down方法需要大量的计算从而导致较慢的定位速度。
Bottom-Up方法就是为了解决这些问题而提出的,一个标准的Bottom-Up方法(如下图)由两部分构成:分别为backbone和head network。前者通常采用co-attention或者cross-gating机制将query的语义和视频的每一帧关联起来;backbone的输出(query-ref frame sequence)经过LSTM/RNN编码之后将会进入head network,该网络预测每一帧视频作为“开始/结束”标签的概率。
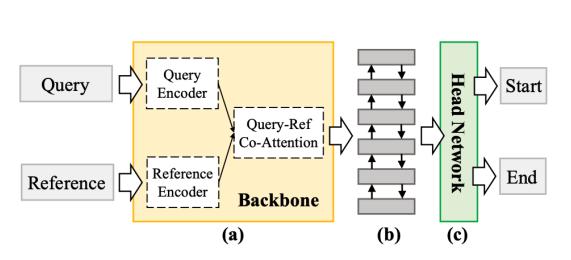
图 1 标准Bottom-Up架构
作者认为,当前的Bottom-Up方法表现不及Top-Down方法的原因在于两部分网络设计的缺陷。
关于backbone:
-backbone仅仅使用RNN/LSTM对视频帧(frame)之间的相互关系进行建模,而忽略了场景(scene, a cluster of frames)之间的相互关系;
-backbone中采用的大多是低维特征向量,而Bottom-Up框架需要更加高维的语义信息来进行视频定位。
关于head network:
-对每一帧视频进行“开始/结束”标记的分类,现有数据的ground truth是一个极度不平衡的数据集;
-对于开始帧和结束帧的标注在已知方法中是独立的,这显然导致模型忽略了截取视频内容的一致性。
全新Bottom-Up模型Graph-FPN with Dense Predictions(GDP)
本文提出的模型GDP在两个部分都进行了改进,下图为GDP的详细图解。
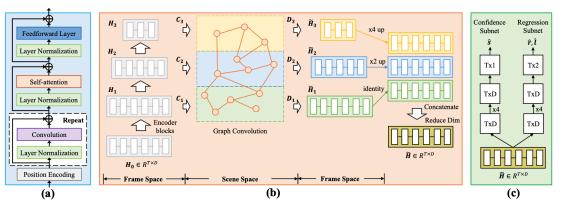
图 2 GDP模型细节
在backbone中,GDP引入了Graph-FPN层来增强backbone的表达能力。该层首先对于query-ref frame sequence构造一个金字塔状的层次化结构来更好地捕捉高维语义信息;接着将这些多规模的帧映射到场景空间(scene space),其中一个节点代表了一个场景;最后在这个场景空间进行图卷积,从而对场景间的相互关系进行有效的建模。
在head network中,GDP将原先的稀疏分布预测替换成了稠密的预测:它将所有在“开始/结束”标记的之间的视频帧认为是正样本(foreground),其余的认为是负样本(background)。同时,每一帧都会对自己作为边界(boundary)的自信度进行打分。这样一来就解决了之前提到的Bottom-Up模型的样本分布不均匀的问题。
多个测试集表现超越SOTA
本文工作在两大类任务,自然语言视频定位(Natural Language Video Localization)以及视频重定位(Video Relocalizaiton )的多个数据集(TACoS, Charades-STA, ActivityNet Captions, and Activity- VRL )上进行测试,表现均优于SOTA模型,以下是具体的表现。
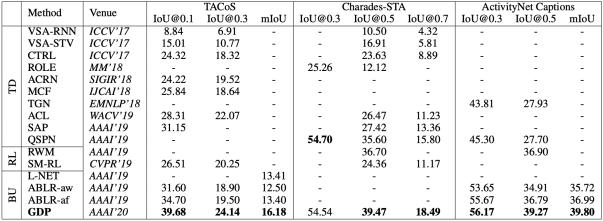
表 1自然语言视频定位任务:GDP模型在3个数据集的9个指标中获得8个最佳
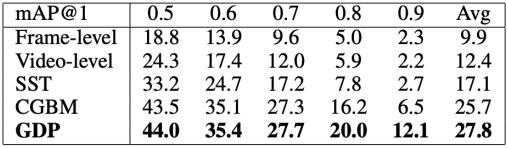
表 2 视频重定位任务:GDP模型在6个指标中均为最佳
再来看看head network是否稀疏的消融实验结果(见表3),在多个任务的多个数据集中,使用了Dense head network的模型普遍有更为优秀的表现。
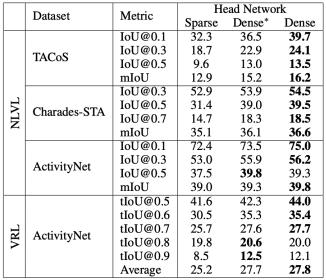
表 3 和稀疏head network模型的比较
最后我们来看一下使用GDP模型的效果,我们可以看到GDP对于该帧是否被ground truth包含的分类score总是倾向于在这一段ground truth正中间,是一个比较好的表现。

图 3 实验结果展示
来源为金融界财经频道的作品,均为版权作品,未经书面授权禁止任何媒体转载,否则视为侵权!
免责声明:本网站所有信息仅供参考,不做交易和服务的根据,如自行使用本网资料发生偏差,本站概不负责,亦不负任何法律责任。涉及到版权或其他问题,请及时联系我们。
相关推荐



猜你喜欢









-
海外网评:50万条逝去的生命,美国无法治愈之痛

2021-02-23 19:48:58
-
福岛强震后,日本石油化工厂附近现血色天空(图)

2021-02-23 19:48:54
-
英国宣布解除严格管控计划后 境外旅行预定猛增

2021-02-23 19:48:52
-
日本自杀率11年来首次上升 内阁任命首位"孤独大臣"

2021-02-23 19:48:44
-
印媒炒作:为对抗中国 印度“悄悄成立”一个专门组织

2021-02-23 19:48:43